使用我们的多账号浏览器,轻松实现多平台创建和管理多个账号
简单好用的指纹浏览器,适用于数据爬取和多类型自动化任务
用安卓云手机运行桌面端的指纹浏览器,独立配置文件,一键防账号关联
无需 VPN 或实体设备,使用内置住宅全局IP在全球多个地区开展运营
助您运行数千个账号环境,自动填写表单、采集数据
输入指令,让 Multilogin 为您自动服务
只需一个控制后台,轻松管理数百个移动端和网页端社媒账号
助您跨平台轻松管理多个亚马逊、Temu、SHEIN等店铺账号
无痕操作,匿名在社交媒体和论坛发布正面评论,提升品牌形象
助您管理成百上千个账号环境,面向不同粉丝群体或受众群体投放更精准的广告内容
创建不限数量的账号,为您同时排多个队,抢占先机
助您隐藏浏览器指纹,轻松通过机器人检测,安全开展高强度网页数据采集
用独立浏览器配置文件或云手机,直接创建和运行多个Telegram账号
在同一台设备上创建管理多个 SHEIN 账号,不用再担心账号关联
通过我们强大的知识库了解如何使用Multilogin
查看我们的服务状态和维护工作公告
利用我们专为开发人员设计的API文档,立即开始Multilogin浏览器自动化
Multilogin搭配各大社媒与电商平台最新使用指南。
Multilogin 的网页爬虫技术帮助您隐藏浏览器指纹、配备可不停切换的全局IP,绝对安全。您可以运行真实浏览器会话,轻松通过机器人检测。我们这一技术专为高强度网页数据采集而研发,即使您需要使用拥有严格反爬机制的网站,我们也能保障您稳定运行数据抓取。
Multilogin 能够隐藏您的浏览器指纹、切换可靠的全局IP,让您丝滑运行接近真实用户行为的浏览器会话。Multilogin 专为大规模数据采集场景打造,即便面对拥有严格反爬机制的网站,也能稳定运行。您可以更安全地采集价格数据、商品信息、或潜在客户的信息,无需再担心被封锁。
Multilogin 为您提供优质的住宅IP资源,超过 95% 的IP拥有干净记录,可用性高达 99.99%。也就是说,当您进行大规模数据采集时,页面加载速度会更快、带宽浪费与请求失败次数会更少、封号概率也会更低。
仅需 1 秒的超快响应速度、覆盖 150+ 国家、超过 3000 万个 IP 资源,助您无障碍采集全球电商平台数据。您可以轻松分析全球不同地区的市场趋势,并针对特定区域优化商品策略。
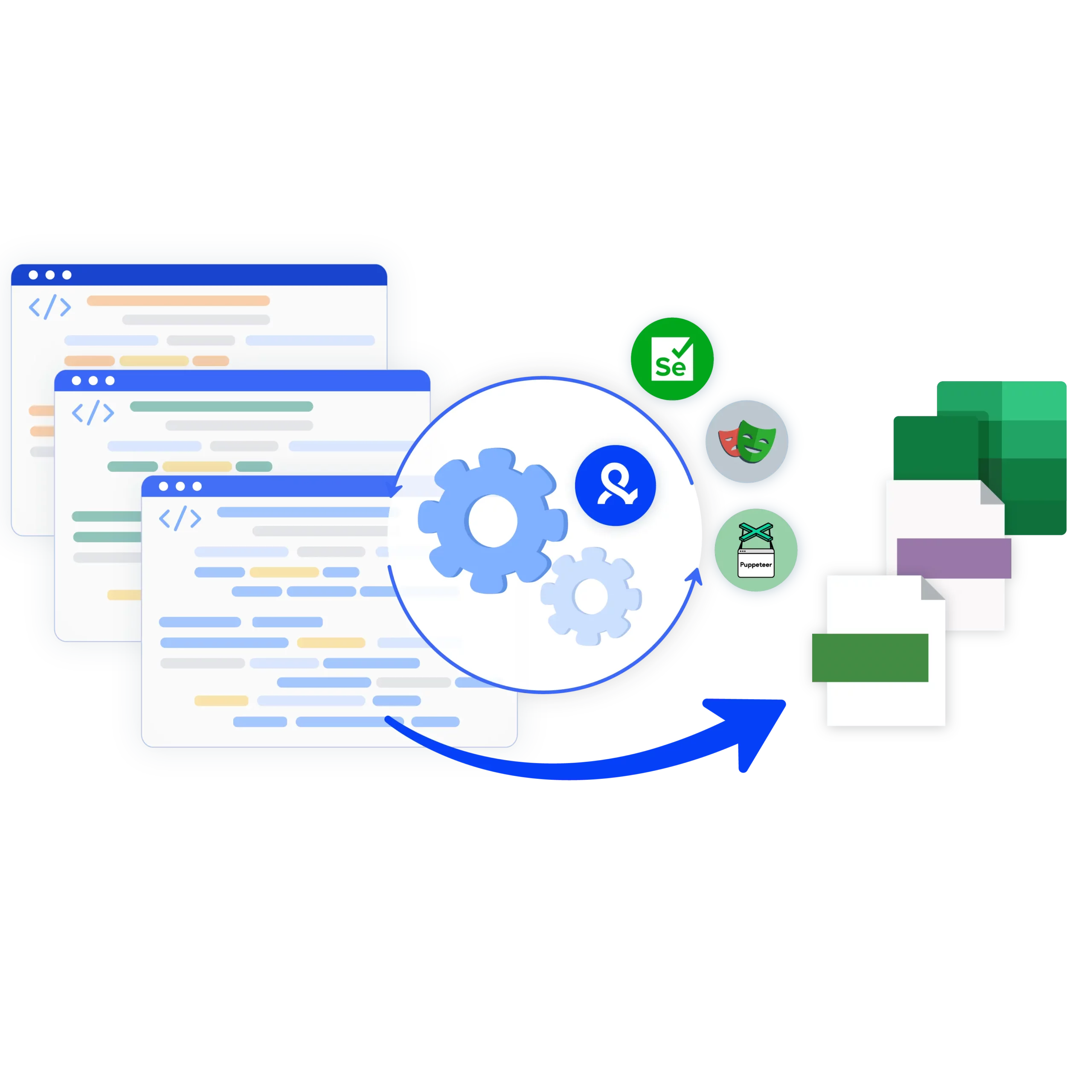
我们的软件 Multilogin X 支持支持单次 API 调用,并兼容 Selenium、Postman、Puppeteer 与 Playwright 等自动化工具。您可以随时一键启动本地环境配置的浏览器配置文件。
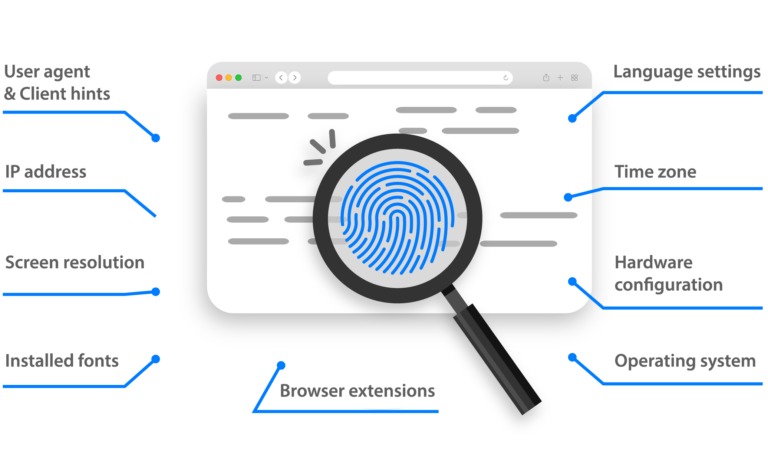
指纹浏览器能够隐藏您设备的“数字指纹”,其中包括浏览历史、Cookies 以及硬件信息等内容。因此,即使所有账号都在同一台设备上运行,每个账号依然会拥有各自独立的身份环境。这就像同时拥有一组彼此独立的匿名用户,可以更安全地领取免费token,同时降低被平台检测到的风险。
Multilogin 为您提供一套安全管理账号与采集数据所需的完整工具。有了Multilogin,您相当于同时拥有了:自带独立指纹的真实浏览器环境、绕过反爬机制的内置住宅全局IP、丝滑协同 Puppeteer、Playwright、Postman 与 Selenium 的工具。Multilogin 助您更稳定地开展自动化与数据采集工作。
一切尽在掌控:支持拖拽、快捷键与流畅多任务操作,保证您的账号高效运行。
借助先进引擎生成独特浏览器指纹,有效降低多账号被识别的风险。
Multilogin 24小时不间断为您服务。
互联网,小型企业
营销代理,小型企业
联合创始人|小型企业
项目经理,小型企业
网页爬虫(Web Scraping)是指通过自动化从网站中收集数据。与手动复制网页信息不同,您可以使用脚本或数据采集工具,自动获取所需内容,例如商品价格、搜索结果、用户评论或社交媒体内容。
从原理上来说,数据采集程序会向网页发送请求,下载页面内容(通常是 HTML),然后提取其中的特定元素,例如标题、价格或商品描述。
但数据采集不仅仅是“获取数据”这么简单,更关键的是:如何高效执行、大规模运行、以及降低被平台封锁的风险。
几年前,简单的 Python 脚本加上每秒发起几个请求,通常就足以完成网页数据采集。但如今,大多数现代网站都部署了更复杂的反爬系统,它们会重点检测以下行为:
重复使用的 IP 或异常地理定位
典型无头浏览器操作
自动化行为模式(例如没有鼠标移动、点击速度异常快)
异常会话行为
重复或可疑的浏览器指纹
这意味着,您的采集程序甚至在真正开始获取数据之前,就可能已经被平台识别。一旦触发风控,您通常会遇到:CAPTCHA 验证、页面重定向、虚假数据、IP 封禁等各种限制。
Multilogin 是一个专注于浏览器自动化与指纹控制的平台,能够让您的流量行为更接近真实用户。我们结合了真实浏览器环境、独立指纹以及记录干净的住宅IP。因此,即使您进行大规模数据采集,也不用提心吊胆,担心触发平台风控。
您可以配合 Selenium、Playwright、Puppeteer 或 Postman 等工具来一起执行自动化采集流程,而 Multilogin 则会在后台负责为您管理浏览器会话环境。每个会话都会运行在独立隔离环境中,并拥有独立 Cookies、独立存储数据、独立时区设置、独立 User-Agent 信息。
这种配置能够呈现:
更接近真实用户的行为环境
本地化 IP 与指纹组合
保持固定IP的持久会话和长期登录状态
在拥有严格反爬机制的网站中依然保持稳定采集效果
简单来说,您的采集程序将不再那么像“机器人”,不用再担心被平台限制。
Python 是最受欢迎的网页数据采集语言之一,因为它语法简单,同时拥有强大的生态工具库。无论您使用的是 BeautifulSoup、Scrapy 还是 Requests,Python 都能够帮助您更轻松地发送网页请求、解析 HTML 内容、导出采集数据。
如果您需要采集动态网站(比如通过 JavaScript 加载内容的网站)的数据,通常需要使用浏览器自动化工具,比如 Selenium Web Scraping。
有了 Selenium,您可以控制真实浏览器(例如 Chrome 或 Firefox),进行点击按钮、填写表单、页面滚动等真实用户操作。因为有些数据只有在用户交互后才会加载,所以这样的操作对采集这类数据来说非常关键。
Multilogin 可以和 Python 脚本及自动化库进行丝滑的协同工作。我们帮助您创建独立浏览器配置文件,并通过 API 启动 Python 脚本来管理这些浏览器环境。也就是说,在脚本运行过程中,您可以自动切换不同的指纹与IP环境,而无需手动切换或启动新的环境。
市面上已有的爬虫工具功能各有不同。而一款优秀的爬虫工具,应当能够为您:
而 Multilogin 拥有以上全部特质。有了 Multilogin,您既可以使用自己已有的全局IP,也可以直接使用 Multilogin 内置的住宅全局IP资源。同时,我们还支持兼容您常用的自动化驱动工具,帮助您解决常见的爬虫问题,比如会话失效、CAPTCHA 循环验证、数据采集不完整。
如今,网络爬虫正在助力越来越多的团队变现商机。以下列举一些最常见的商业数据采集场景:
所有这些场景,都需要团队在大规模爬虫的同时,尽可能避免被平台封号或限制 IP、获取虚假数据。因此,一个可靠的爬虫体系已经离不开浏览器指纹控制、全局IP切换和稳定的浏览器环境。如今各大平台反爬机制愈发严格,以上提到的技术已经是必不可少的基础配置。
网页爬虫API 能够帮助您更轻松地从网站提取数据。它会替您处理数据采集过程中较为复杂的部分。
而 Multilogin 能够与多种 API 配合使用,从而提升您数据采集的效率,并帮助您更稳定地获取网页数据。
JavaScript 网页爬虫主要适用于那些通过脚本动态加载内容的网站,而不是传统静态 HTML 页面。针对动态网站,您一般需要更复杂的采集方案,因为基础的工具往往无法获取隐藏在 JavaScript 渲染之后的数据。
Multilogin 的指纹浏览器正是为此设计的。我们能够帮助您更稳定地访问、渲染并提取页面中的完整信息,无需担心遗漏关键数据遗漏。
如果您真的想长期稳定地网页爬虫,只拥有代码远远不够。您还需要一套能够支持规模化运行的基础配置,以免在此过程中不断被平台限制。
Multilogin 有所有您需要的配置:
完整的浏览器指纹体系(操作系统、字体、语言、WebGL、分辨率等),可根据您的需求个性化定制
通过 API 自动启动与管理浏览器会话
支持持久会话、切换全局IP,适用于长期任务
会话隔离机制:避免不同环境之间的 Cookies、缓存与存储数据相互交叉
兼容 Postman、Puppeteer、Selenium 与 Playwright 等工具
有了以上配置,您可以在同一台设备上轻松同时运行多个网页爬虫机器人,并让每个机器人都拥有独立身份环境。同时,机器人们的操作依然会像真实用户一样,而不会轻易被被识别成自动化流量。
Multilogin 让您的每个浏览器会话都更接近真实独立用户,从而提升您进行网页爬虫的稳定性与成功率。MUltilogin 和那些使用通用 User-Agent 或无头浏览器、容易触发平台风控的工具不同,我们会为您的每个会话分配独立浏览器指纹和记录干净的住宅IP。这能够极大降低您被平台检测、封号或得到虚假数据的概率,特别是在那些拥有严格反爬机制的网站上。您可以把我们和 Puppeteer、Playwright 或 Selenium 等自动化工具结合使用,更稳定地扩展您的网页爬虫任务,而无需担心频繁遇到限制。
数据采集是指从网站中提取信息的过程。有了数据采集,您就不用再手动复制网页内容,而可以通过脚本或软件自动获取特定数据,例如:商品信息、价格、用户评论、邮箱信息。
如今,大部分数据采集流程都已经实现自动化。像 Selenium 或 Python 脚本这样的工具负责执行具体的采集任务,而我们 Multilogin 这类平台则能够帮助您在采集过程中降低被平台封锁的风险。
爬虫本身是合法的。但具体是否有法律风险,取决于采集数据的具体类型和采集的方式。一般来说,对公开网页进行数据采集风险相对较低;但一旦涉及私有内容、受版权保护的数据、违反网站服务条款的行为,则可能带来法律风险。
最稳妥的做法,是以负责任的方式采集公开、无需登录即可访问的内容。Multilogin 能够通过模拟真实浏览器行为,帮助您降低触发反爬系统的概率,但我们无法替代必要的法律合规判断与风险评估。
具体哪款工具最适合您,取决于您的技术背景以及项目需求:
Python 用户通常会选择 BeautifulSoup、Scrapy 或 Selenium
如果您的项目需求以浏览器自动化为主,那么 Playwright 与 Puppeteer 都是非常合适的选择
如果您主要跟 API 打交道,那么 Postman 这类工具会更适合测试与自动化流程
Multilogin 能够与这些工具协同工作,帮助您降低被平台检测到的风险。您可以通过 API 启动真实的浏览器配置文件、切换全局IP,并更稳定地大规模运行自动化脚本,而不用担心被平台限制。
网站之所以会封锁爬虫工具,通常是因为检测到了异常行为,比如请求频率过高、浏览器指纹与 IP 信息不匹配、使用已被标记的数据中心 IP。一旦触发风控,您可能会遇到CAPTCHA 验证、虚假数据、IP 封禁。
为了防止这些问题发生,您通常需要:
使用住宅全局IP轮换 IP 环境
让浏览器指纹与 IP 地区保持一致
使用真实的浏览器会话,避免无头浏览器检测
Multilogin 能够帮助您完成这些配置。我们会为您创建拥有干净 IP 与更接近真实用户行为指纹的独立浏览器配置文件,从而让您的网页爬虫流量就像正常用户环境中一样运行。
Multilogin 支持与 Puppeteer、Playwright 和 Selenium 等网页爬虫工具协作。您可以通过 API 启动真实浏览器配置文件、分配全局IP,并在一个工作流中统一管理浏览器会话。节省您的时间,并提升数据采集的成功率。
是的。您可以仅花费 €1.99 (不到14元人民币) 开启 3 天试用。试用期间,您将获得:
所有核心功能访问权限
200MB 住宅全局IP流量
5 个云端或本地浏览器配置文件
这些资源已经足够帮助您在正式订阅前测试爬虫使用。